these days the story everyone tells is: let the model “think” before it answers, and it does better. you give it a scratchpad, it writes out a long chain of reasoning, and accuracy goes up. papers like s1 and snell et al., and the whole o1 narrative, are built on this idea of spending more compute at test time by thinking longer.
while running a budget-forcing study i kept wondering about something simple. when thinking helps, is it because of what the model writes in the scratchpad? or just because it spent a few thousand extra tokens before answering — the extra forward passes, the longer context — regardless of what those tokens say?
so i ran the dumbest possible test.
the test
a “thinking” model answers in two phases. first it writes reasoning inside a <think>...</think> block. then it writes the actual answer.
i kept the answer phase exactly the same, but i replaced the reasoning with random gibberish of the same length — 4096 tokens drawn uniformly at random from the model’s vocabulary. then i let it answer normally and scored it.
three conditions, same models, same problems:
- no thinking — empty scratchpad, answer straight away
- gibberish thinking — scratchpad full of 4096 random tokens
- real thinking — the model’s actual 4096-token reasoning
if gibberish scores like no thinking, then content is everything. if gibberish scores like real thinking, then the content never mattered and it was just the length/compute all along. anywhere in between tells you how the credit splits.
the gibberish really is nonsense. here’s an actual scratchpad (first ~140 chars):
Corner/F Recommended kitt比亚迪蔓arellances(Double.tv.mappingproposal痉挛(hand
muse oversSecret(center DIAG AwardsDeck女儿的 FedEx ""; contextoobook
and here’s what the 9B model wrote right after that gibberish, when it was time to answer:
Dylan bought 38 chicken sausages.
He bought 6 more fish sausages than chicken sausages.
Number of fish sausages = 38 + 6 = 44.
Total sausages = 38 + 44 = 82.
\boxed{82}
it completely ignores the garbage in the scratchpad and just solves the problem in the answer phase.
what happened (on gsm8k)
i tested three qwen models (4B, 9B, 27B) on gsm8k, 400 problems each.
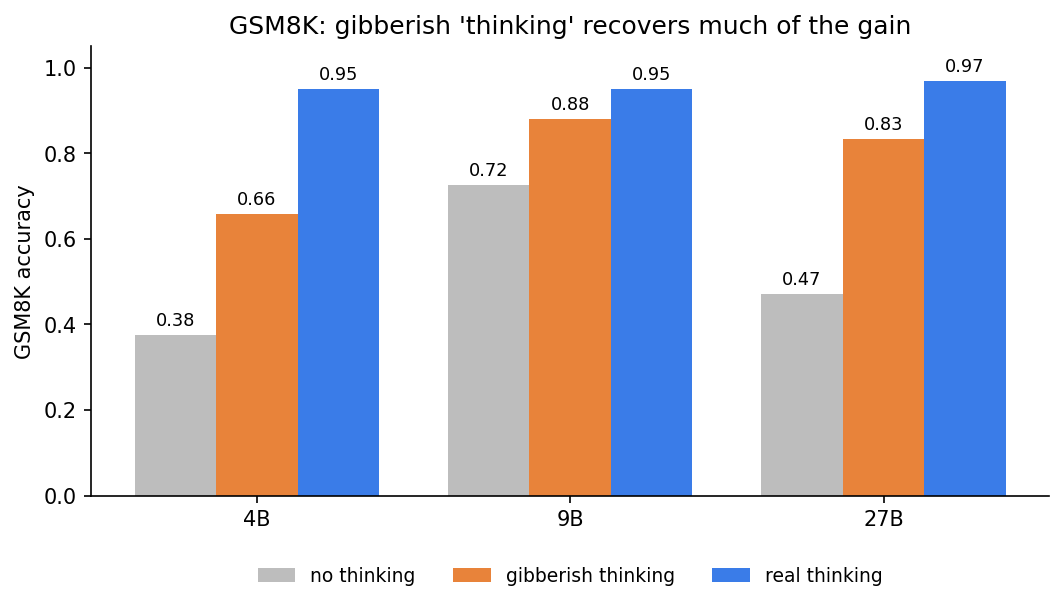
gibberish lands between no-thinking and real-thinking, and not by a little. if you measure how much of the no-thinking → real-thinking gain the gibberish recovers:
- 4B: ~49%
- 9B: ~69%
- 27B: ~73%
so on gsm8k, roughly half to three-quarters of the “thinking helps” gain is content-free — you get it from random tokens of the same length. and oddly, the bigger the model, the more of the gain is content-free.
the takeaway i’d draw: a chunk of what we call “reasoning” on gsm8k is the model just warming up on a longer prefix before it answers, not the reasoning itself doing work. if you want to claim “thinking helped,” the honest baseline isn’t no thinking — it’s gibberish thinking of the same length.
the important caveat: this is a gsm8k thing
before anyone runs off saying “llm reasoning is fake” — it isn’t, and gibberish is not a free lunch. the moment you leave grade-school word problems, gibberish stops helping and starts actively hurting.
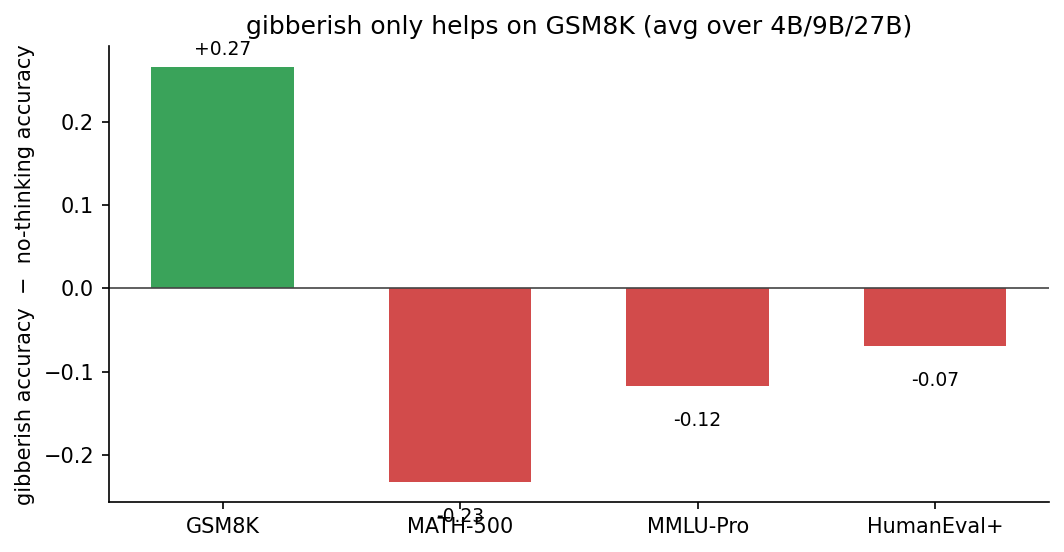
on math-500 (competition math), mmlu-pro (knowledge questions), and humaneval+ (code), filling the scratchpad with gibberish drops accuracy below even the no-thinking baseline. there the content genuinely matters — the random tokens get pulled into the answer and act like noise.
my guess at why gsm8k is different: gsm8k problems are wordy and redundant (“dylan bought 38 chicken sausages…”), so the problem statement survives even with a junk prefix, and the only thing the junk adds is length. compact, precise tasks like proofs or code don’t have that slack. but that’s a hypothesis, not something i proved.
caveats, honestly
- only qwen models (4B / 9B / 27B). no idea if it holds elsewhere.
- one random seed for the gibberish. so treat the exact percentages as ballpark, not decimal-precise. (each accuracy is over 400 problems.)
- the recovery percentage depends on the no-thinking baseline, and the 27B no-thinking number is suspiciously low — lower than the 9B’s — so i’d read the 27B “73%” with some caution.
- “it’s just warmup / length” is my explanation, not a measured fact.
still, i think the simple version holds up: on gsm8k, a lot of the benefit of “thinking” is just spending tokens, and you can prove it with garbage.
references
- muennighoff et al., s1: simple test-time scaling, 2025
- snell et al., scaling llm test-time compute optimally…, 2024
- openai, learning to reason with llms (o1), 2024